

Nello scorso articolo sulla gestione della memoria, ci siamo lasciati accennando alla segmentazione con paginazione, e dicendo che per parlarne avremmo prima dovuto affrontare la memoria virtuale.
Il che è corretto, perché per capire come funziona la segmentazione paginata, dobbiamo conoscere almeno a grandi linee la memoria virtuale.
In questo articolo non andremo molto sul pesante, ma faremo un percorso un po’ in generale, per capire cos’è, come funziona, e i vantaggi della memoria virtuale. Tutto questo per rispondere all’interrogativo dell’articolo precedente.
Cos’è la Memoria Virtuale?
La memoria virtuale è un meccanismo del sistema operativo che permette principalmente di far girare programmi più grandi della RAM. Dà l’illusione ai processi di avere spazio potenzialmente illimitato. Le conseguenze immediate sono queste:
- Possiamo avere processi più grandi dello spazio libero in RAM;
- Possiamo elaborare dati più grandi dello spazio libero in RAM.
Sembra una stregoneria, perché sappiamo che tutto ciò che deve essere elaborato deve risiedere in memoria primaria. Infatti la cosa che rende geniale la memoria virtuale, è che usiamo il disco come se fosse RAM.

In realtà non è proprio così, o meglio non è del tutto corretto.
Dobbiamo dire che usiamo la memoria secondaria per appoggiare temporaneamente pezzi di processi/dati che non ci servono in questo momento, e che probabilmente non ci serviranno per un po’ (ricordi il principio di località?).
Immagina questo scenario:
- Devi eseguire un processo;
- Carichi solamente le prime pagine in RAM;
- Le restanti le allochi sul disco;
- Man mano che il processo richiede altre pagine, le prendi dal disco e le swappi in RAM;
Oppure:
- Hai alcuni processi in RAM;
- Devi caricare un altro processo ma non hai spazio libero;
- Prendi un pezzo di un altro processo, le cui pagine non sono utilizzate da un bel po’ di tempo;
- Nello spazio appena liberato vai a caricare le prime pagine del nuovo processo.
Una bella salvata, no?
Abbiamo appena introdotto un termine: swap, che indica un trasferimento tra memoria primaria e secondaria; più precisamente:
- Swap in: disco –> RAM;
- Swap out: RAM –> disco.
Indirizzamento nella Memoria Virtuale (Segmentazione su Paginazione)
Ora che sappiamo cos’è la memoria virtuale, vediamo di capire come funziona l’indirizzamento.
Dato che usiamo RAM e disco un po’ allo stesso modo, ci conviene avere un indirizzamento che tenga conto di questa proprietà. Infatti gli indirizzi virtuali sono usati sia per indirizzare pagine in RAM che su disco. Magnifico eh 🙂
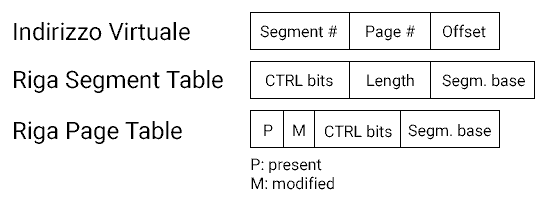
Un indirizzo virtuale è una tripla formata da <numero segmento; numero pagina; offset>.
Al di sotto di questo indirizzo abbiamo i due livelli già familiari di segmentazione e paginazione.
Riga tabella dei segmenti: <bit di controllo; lunghezza; base del segmento>;
Riga tabella delle pagine: <P; M; bit di controllo; numero frame>.
Ci siamo resi conto che l’indirizzamento delle pagine ora è leggermente diverso. In particolare abbiamo aggiunto due bit P ed M.
P (present): indica che quella pagina è attualmente in RAM, e non su disco;M (modified): indica che quella pagina è stata modificata.
Prima di proseguire con la traduzione degli indirizzi, è furbo ricordare che:
- Ogni processo ha la sua tabella dei segmenti, che indirizza punti di partenza e lunghezza dei suoi vari segmenti;
- Ogni processo ha varie tabelle delle pagine, che indirizzano varie pagine;
- Ogni segmento indirizza una specifica tabella delle pagine.
Bene, vediamo lo schema generale dell’indirizzamento.
Se trovi qualcosa che non quadra, ridai una letta alle tre cose che abbiamo ricordato un attimo fa.
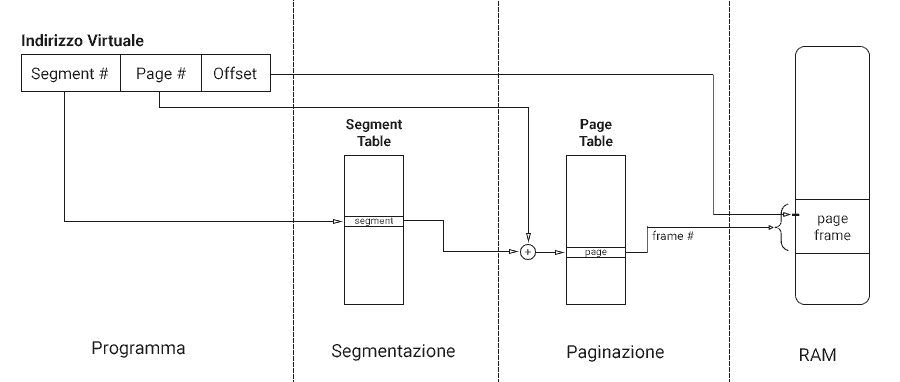
Può essere utile avere una telecronaca dell’immagine appena vista:
- Abbiamo un indirizzo virtuale, quindi: un
numero di segmento, unnumero di paginaed unoffset; - Abbiamo anche il puntatore alla tabella dei segmenti per il processo;
- Prendiamo la tabella dei segmenti, e andiamo alla riga denotata dal
numero di segmento; - In quella riga troviamo l’indirizzo della page table per quel segmento;
- Prendiamo quella tabella delle pagine, e andiamo alla riga denotata dal
numero di pagina; - In quella riga troviamo il
numero di frame; - Perfetto: prendiamo la RAM ed andiamo all’indirizzo denotato da quel
numero di frame, e spostiamoci in base all’offset.
Nice.
Perfetto. Abbiamo finito la prima parte di questo articolo. Passiamo alla seconda ed ultima.
Politiche per lo Swap di Pagine
Ok, sappiamo cos’è lo swap.
Immagina ora di avere una situazione in cui il sistema è in costante stato di swap in e out.
Questo fenomeno si chiama thrashing.
Dato che lo swap è costoso, con il thrashing andiamo a devastare pesantemente le prestazioni del sistema.
Vogliamo evitare tutto ciò, e ci accorgiamo che lì all’angolino c’è sempre il solito principio di località che ci fa l’occhiolino.
Perfetto, usiamo il principio di località per caricare le pagine in modo saggio.
Fetch Policy (politiche di caricamento)
Questo tipo di politica decide come caricare le pagine in RAM.
Quando c’è un riferimento ad una pagina non presente in memoria, abbiamo un page fault, che innesca il meccanismo di fetch, oppure di *replacement *(che vedremo tra poco).
Abbiamo due tipi di fetch policy:
- On-Demand Paging: carica pagina appena viene referenziata; inizialmente provoca molti page fault;
- Prepaging: carica diverse pagine contigue (principio di località, again).
Replacement Policy (politiche di rimpiazzo)
Decide quale pagina rimpiazzare, se necessario.
Queste politiche sono abbastanza importanti, infatti abbiamo diversi algoritmi per realizzarle.
La bontà di un algoritmo è determinata dal numero di page fault che innesca.
Le pagine sostituite vengono poi inserite in un page buffer, che tipicamente divide tra pagine modificate e non.
Dopo un page fault, prima di caricare la pagina dal disco, il gestore della memoria ne controlla la presenza nel page buffer.
Vediamo questi cinque algoritmi di rimpiazzo delle pagine.
OPT (Sostituzione ottimale)
È un’utopistica sostituzione ottimale delle pagine.
Non è realizzabile, perché prevede la sostituzione della pagina che verrà usata più tardi, che non possiamo sapere.
LRU (Least Recently Used)
Sostituisce la pagina meno usata di recente.
Ha bisogno di un’etichetta che rappresenti il tempo di utilizzo.
FIFO (First In – First Out)
Sostituisce la pagina presente in memoria da più tempo. È come un buffer circolare.
Semplice e carino, peccato che non sfrutta il principio di località. Quindi ci fa schifo.
Clock
Su questo algoritmo c’è un po’ di più da dire. Lo chiamiamo clock perché possiamo rappresentarlo graficamente come un orologio in cui:
- Al posto dei numeri abbiamo pagine;
- Ad ogni pagina è assegnato un use bit (o reference bit) con valori {0, 1}
- La lancetta funge da puntatore.
Da un punto di vista generale, possiamo dire che l’algoritmo di clock funziona così:
- Il puntatore punta alla pagina più vecchia;
- Inizialmente l’use bit è 0;
- Quando si referenzia una pagina, il suo bit incrementa ad 1; il bit delle pagine incontrate dal puntatore (lancetta) fino alla pagina referenziata viene settato a 0;
- La pagina da rimpiazzare è la prima che la lancetta incontra con use bit a 0.
Questo algoritmo è anche chiamato second chance, perché alle pagine con use bit 1 viene data una seconda possibilità di rimanere in memoria.
Qui abbiamo un’ottima illustrazione sia dell’algoritmo clock che g-clock:
G-Clock
L’algoritmo Generalized Clock è – appunto – una versione generalizzata del clock, in cui:
- L’use bit ha valori nel range [0, infinito);
- La pagina referenziata incrementa il contatore, e tutti quelli incontrati dalla lancetta vengono decrementati;
- La pagina da rimpiazzare è la prima con use bit 0.
Come scritto poco fa, puoi trovare l’illustrazione di questo algoritmo nel video precedente.
Ricapitoliamo gli algoritmi di sostituzione delle pagine
Perfetto, prima di toglierceli di torno, vediamo al volo un esempio pratico.
Supponiamo di avere spazio per tre pagine, e vediamo il comportamento di questi algoritmi a confronto.
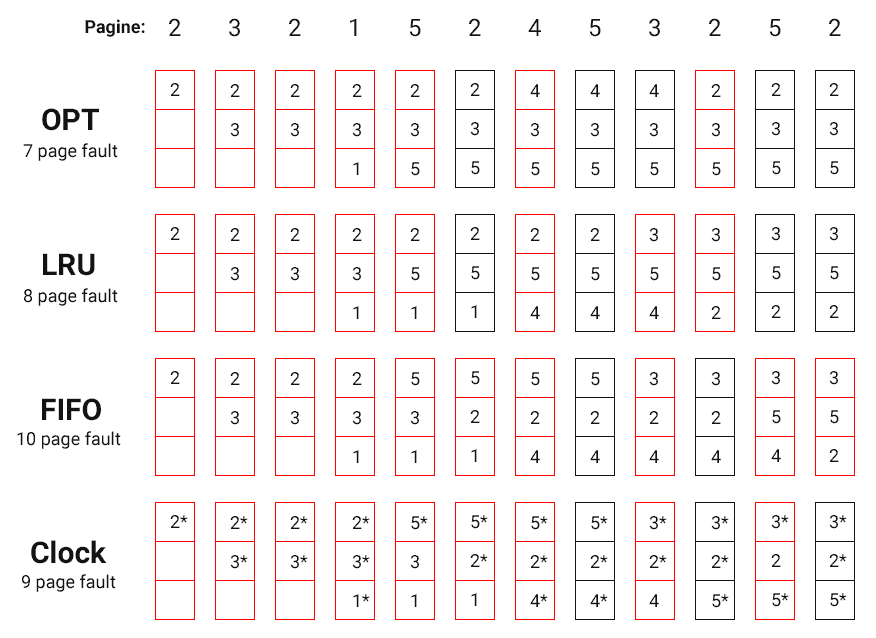
Come hai osservato, all’inizio abbiamo esattamente gli stessi page fault (indicati in rosso); è normale, perché vengono referenziate pagine che ancora non abbiamo in memoria.
Troviamo differenze dalla quinta richiesta in poi.
In questo particolare esempio, vince l’algoritmo LRU (ce ne freghiamo dell’OPT), ma non è sempre così.
Osservazione sui benefici di avere pagine piccole
Ora che conosciamo bene:
- Paginazione;
- Segmentazione;
- Memoria Virtuale;
- Segmentazione su Paginazione;
- Significato di page fault;
- Principio di località;
- Importanza delle replacement policy.
Possiamo fare una piccola osservazione sui benefici di avere pagine piccole.
Avere pagine piccole comporta:
- Minor frammentazione interna;
- Process Page Table più grandi:
- PPT grandi su disco, e il disco è ottimizzato per trasferimenti in blocco (quindi di grandi quantità); quindi siamo felici.
- Più pagine caricabili in memoria:
- Pochi page fault.
Che possiamo riassumere in modo più gradevole con quest’immagine.
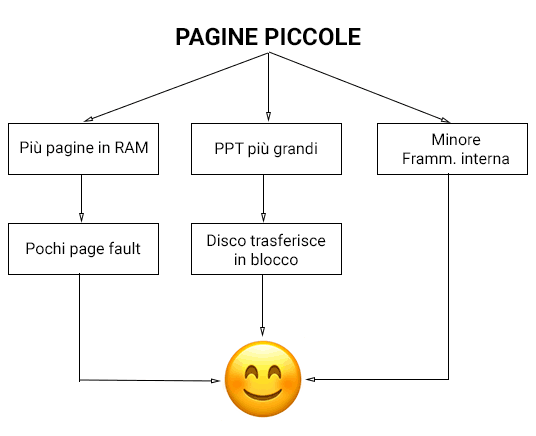
Insomma è proprio carino avere pagine piccoline.
Conclusione
Splendido: con questo articolo e il precedente abbiamo concluso il discorso sulla gestione della memoria. È molto probabile che io continui a scrivere roba di questo tipo sui sistemi operativi. Se vuoi essere avvisato quando li pubblicherò, iscriviti al volo alle newsletter (sono poche, concise e non invasive).
In ogni caso, grazie per aver letto fino alla fine :).
Se hai apprezzato l’articolo, che ne dici di condividerlo? Saresti tipo un eroe.
Per qualsiasi cosa, sentiti libero di lasciare un commento.
Licenze per le icone usate nelle immagini: RAM e Hard Disk by Double-J Design, con licenza CC BY 4.0.
