

La gestione della memoria principale (RAM, primaria, o come vogliamo chiamarla) è uno degli aspetti più importanti dei sistemi operativi. Come tutte le risorse di un computer, anche la RAM deve essere gestita secondo i soliti principi di equità e prestazioni.
In particolare, la gestione della memoria deve:
- Essere economica (basso overhead);
- Massimizzarne l'uso.
Detto un po' meglio, non si deve sprecare tempo CPU per mettere e togliere roba dalla memoria primaria, e si deve usare tutto lo spazio a disposizione in modo efficiente.
Prima di iniziare a parlare più concretamente, ci serve qualche piccolo formalismo. Andiamo.
Qualche concetto di base
Per parlare della gestione della memoria useremo spesso dei termini specifici. Non è detto che tutti li conoscano, per questo metto qui un piccolo glossario che può far comodo.
- Allocare: memorizzare qualcosa in memoria;
- Deallocare: rimuovere qualcosa dalla memoria;
- Indirizzo [di memoria]: indirizzo esadecimale che corrisponde ad un preciso punto nella memoria.
Perfetto, entriamo un po' più nel dettaglio.
Requisiti per la Gestione della Memoria
Per garantire efficienza e facilità di gestione, protezione di dati, e un minimo di portabilità del codice, abbiamo bisogno di questi bei requisiti.
Protezione e Condivisione
Generalmente, non vogliamo che un processo possa accedere ad aree di memoria di altri processi.
Immagina di avere un password manager in esecuzione: in RAM hai sicuramente le tue credenziali in chiaro; sono sicuro che non gradiresti che un qualsiasi processo possa accedere a quel pezzo di memoria, e leggere le tue credenziali.

Allo stesso tempo però, vogliamo anche far sì che alcune zone di memoria siano condivise tra processi.
Immagina di avere una libreria grande 500 kB, che viene usata da 20 processi: invece di avere la libreria copiata in ognuno dei 20 processi (per cui 500*20 kB = 10 MB), la lasciamo condivisa e risparmiamo almeno 10 MB.
Ho unito questi due requisiti in un unico punto perché sono strettamente correlati. Appena parliamo di condivisione, introduciamo anche il concetto di protezione, e viceversa.
Rilocazione
Questo è un bel concetto; vediamo che significa.
Sappiamo che:
- La dimensione della RAM non è la stessa per ogni dispositivo;
- Il sistema operativo decide dove allocare in memoria;
- Un processo può essere tolto dalla memoria, e rimesso in seguito (swapping);
Di conseguenza abbiamo che la zona che un processo occuperà in memoria non è mai certa. Non è per niente prevedibile.
Ma un processo deve essere eseguito normalmente, a prescindere dalla sua posizione in memoria.
Un processo deve poter eseguire le sue istruzioni senza pensare a dove realmente esse siano in RAM.
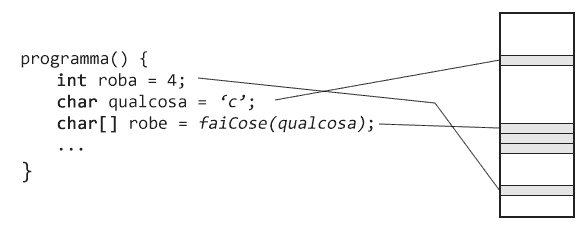
Questa è l'essenza della rilocazione: rendere il processo indipendente dalla sua posizione in memoria.
In particolare, la visione di un processo è confinata alla sua area di memoria, quindi a quella delimitata dall'indirizzo della prima istruzione e quello dell'ultima. Queste due informazioni vengono memorizzate in due registri specializzati, chiamati rispettivamente base register e bounds register.
In pratica, si mette in atto la rilocazione introducendo degli indirizzi relativi, chiamati anche logici.
Il processo usa questi indirizzi relativi, che poi vengono tradotti dal sistema operativo in indirizzi fisici reali.
Osserviamo che parlando di rilocazione, abbiamo anche – implicitamente – parlato di protezione della memoria.
Per finire questo concetto, parliamo dei due tipi di rilocazione.
Rilocazione Statica
Primitiva e brutta. In fase di caricamento del processo, tutti gli indirizzi logici vengono tradotti in fisici, calcolandoli a partire da quello iniziale.
- Pro: nessuno;
- Contro: il processo non è swappabile –> la memoria non può essere riorganizzata.
Rilocazione Dinamica
Carina e moderna. Traduciamo gli indirizzi a runtime.
- Pro: possiamo rilocare il processo in giro per la RAM –> possiamo riorganizzare la memoria;
- Contro: nessuno.
Organizzazione della Memoria
Dobbiamo distinguere tra quella fisica e logica.
- Fisicamente, in memoria attuiamo l'overlaying, ovvero possiamo allocare diversi moduli/processi nella stessa zona di memoria, ma in tempi diversi. Inoltre la gestione viene fatta in maniera trasparente all'utente/programmatore.
- Logicamente, vediamo la memoria in modo lineare, con permessi per ciascun modulo/processo.
Ottimo, ci siamo levati la parte più pallosa e prolissa.
Un applauso a te che stai ancora leggendo. Questo è per te:

Ora le cose iniziano a farsi un po' serie.
Gestione della Memoria (ora ci siamo)
La memoria primaria è uno spazio lineare in cui il sistema operativo alloca e dealloca robe. Queste due operazioni sembrano molto banali a parole, ma in realtà sono un bel problema.
Negli anni sono state introdotte diverse idee per rendere possibili queste operazioni. I sistemi operativi moderni usano delle tecniche chiamate segmentazione e paginazione (anche usate insieme), che consentono di usare la memoria principale con efficienza e senza sprechi.
Ma non è stato sempre così. Inizialmente siamo partiti con una tecnica abbastanza primitiva, ma che all'epoca poteva anche andare bene: il partizionamento.
Ora inizieremo da questo concetto, ed arriveremo pian piano alle tecniche di oggi.
Partizionamento della Memoria
L'idea di fondo di questa tecnica cavernicola, era di dividere la RAM in blocchi di una certa lunghezza, chiamati partizioni.
Le caratteristiche principali erano:
- Un programma in ogni partizione;
- No programmi a cavallo di partizioni.
Avevamo tre tipi di partizionamento:
- Fisso;
- Variabile (fisso a dimensione variabile);
- Dinamico.
Ti anticipo che i primi due sono molto simili, ed hanno più o meno gli stessi problemi e limitazioni, mentre il terzo è leggermente più carino.
Partizionamento Fisso
L'idea era di avere partizioni di lunghezza fissa.
Questa tecnica richiedeva un supporto hardware non da poco: infatti le memorie RAM dovevano uscire dalla fabbrica già partizionate.
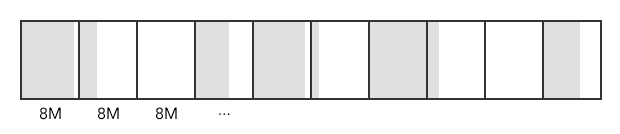
È anche abbastanza intuitivo capire le limitazioni:
- Numero limitato di processi caricati simultaneamente in memoria;
- Dimensione massima dei processi data dalla grandezza delle partizioni.
Inoltre, qui si introduce un problema chiamato frammentazione interna: come puoi vedere dall'immagine, abbiamo diversi processi che sono più piccoli delle partizioni, quindi in ogni partizione abbiamo dello spazio non utilizzabile.
La gestione delle memoria in questo caso non è neanche lontanamente efficiente. Sembra di buttare all'aria metà di questo articolo. Ma procediamo con ordine.
Partizionamento Variabile
Qualche persona intelligente si era resa conto che c'era un modo abbastanza intuitivo per ridurre la frammentazione interna.
Il ragionamento di questo/a signore/a era all'incirca così:
Se abbiamo frammentazione interna, significa che abbiamo programmi più piccoli delle partizioni.
Allora, se avessimo partizioni con lunghezze diverse, potremmo allocare i programmi nelle partizioni di dimensione più simile.
Magnifico, meraviglioso. Ecco l'idea rappresentata graficamente.
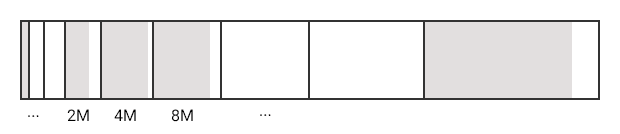
Avevamo sempre un numero fisso di partizioni, ma le loro dimensioni erano incrementali.
Questa roba poteva essere gestita con una coda globale, oppure una coda per ogni partizione.
In ogni caso, anche questo metodo ha dei problemi seri:
- Riduce la frammentazione interna, ma non la risolve;
- Richiedeva ancora un un partizionamento a livello hardware;
- Numero limitato di processi;
- Dimensione massima del processo fissata;
Il caso peggiore di questa tecnica consiste nell'avere molti processi piccoli, o molti grandi.
In questo caso, tutti questi processi faranno a gara per accaparrarsi la partizione per loro migliore (che è la stessa).
Terrificante.
Partizionamento Dinamico
Un'altra persona un intelligente, a questo punto ha detto:
Eh no ragazzi, non possiamo continuare così. Questi metodi non sono scalabili e sono pieni di problemi. Perché non ci svincoliamo da queste robe fisse ed antiche?
Ed ecco che qualcuno si è inventato il partizionamento dinamico. Eccolo qui nel suo splendore.

Che bello, guarda che bellezza:
- Non servono più memorie già partizionate;
- **Partizioni create ad-hoc **a runtime;
- Addio frammentazione interna;
- Addio limiti di processi;
- Ora la grandezza massima del processo coincide con la dimensione della RAM;
Oh no, abbiamo frammentazione esterna :(.
Immagina qualcosa come:
- Sei processi Pi con i=1…6 vengono allocati dove il SO decide;
- Ad un certo punto P2 termina, e viene deallocato –> buco lasciato da P2;
- Arriva P6 e deve essere allocato:
- Non riesce ad entrare nel buco, perché è troppo grande;
- Viene allocato dopo P5, perché è l'unico posto in cui riesce ad entrare.
- P5 passa una certa fase, e libera un po' di memoria –> buco tra P5 e P6;
- Arriva un nuovo processo P7, che riesce ad entrare nel buco tra P2 e P3:
- Viene allocato lì dentro;
- Il buco si restringe, ma la sua nuova dimensione è troppo piccola per accogliere altri processi.
- …
Questa situazione è un esempio per esporre il problema della frammentazione esterna.
Immagina una libreria in cui metti e togli libri, oppure li sposti. Prima o poi arriverai ad un bel casino in cui hai:
- Buchi;
- Disordine.
Per questo ogni tanto dobbiamo fare un'operazione chiamata compattazione, che riordina tutto in modo da non avere buchi.
Il problema è che la compattazione ha un overhead alto; in pratica, è un'operazione costosa, e non possiamo permetterci di farla molto spesso.
Infatti esistono diversi algoritmi per decidere dove allocare nuovi pezzi di processo. Sono tantissimi: quattro.
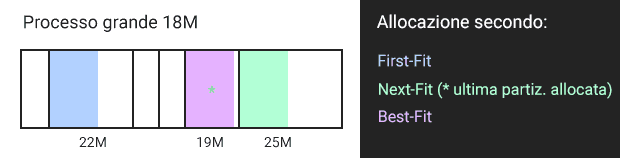
Best-Fit
- Processo allocato nello spazio più piccolo che lo può contenere (il migliore, per definizione);
- Alto overhead, perché trovare questo spazio richiede tempo;
- A lungo termine ci porta più frammentazione esterna;
First-Fit
- Processo allocato nel primo spazio libero a partire dall'inizio della memoria;
- Basso overhead;
- A lungo termine tende ad affollare la parte iniziale della RAM;
Next-Fit
- Come il first-fit, ma a partire dall'ultima posizione allocata (idea derivata dal principio di località);
- Basso overhead;
- A lungo termine tende ad affollare la parte finale della RAM.
Buddy System
Questa tecnica è un po' più complessa delle precedenti, e l'idea di base consiste nel dividere la memoria in blocchi chiamati buddies, ed allocarci il processo se rispetta una certa condizione. Vediamolo meglio:
- Tratta la memoria come un blocco lungo 2u;
- Se un processo richiede di allocare uno spazio s, tale che 2u-1 < s < 2u, alloca l'intero spazio;
- Altrimenti, spezza la memoria libera in due buddies lunghi 2u/2, e procedi ricorsivamente.
Detto in parole umane: se il processo è più grande della metà dello spazio libero, allocalo lì; altrimenti spezza in due lo spazio libero ed applica ricorsivamente la regola.
Paginazione della Memoria
Finalmente siamo arrivati alle cose serie.
Se ci piacciono le comparazioni, possiamo dire che questa tecnica usa alcuni principi del partizionamento fisso, ma in chiave moderna.
Sì, forse questa descrizione è più adatta a recensire un album musicale, ma non è sbagliata. Vediamo perché.
Con la paginazione, sia la memoria che i processi vengono suddivisi in **piccoli blocchi di dimensione fissa **(tipicamente 512 kB);
Introduciamo al volo la terminologia:
- Pezzi di memoria: pagine;
- Pezzi di processo: frame.
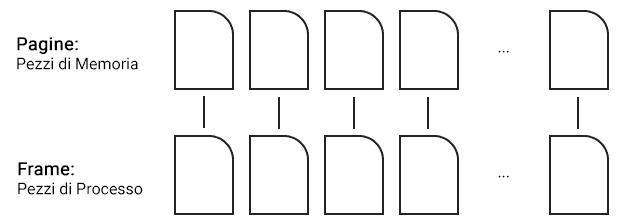
Per ogni processo il sistema operativo mantiene una tabella delle pagine, che mappa frame a pagine.
Possiamo vedere un indirizzo di memoria come una coppia formata da <numero di pagina; offset>.
Dato che questo sistema è l'erede del partizionamento fisso, ci portiamo dietro il problema della frammentazione interna, ma talmente ridotto (data la dimensione delle pagine) che possiamo trascurarlo e non pensarci.
Segmentazione della Memoria
Quest'altro sistema è invece erede del partizionamento dinamico.
Infatti ogni processo viene suddiviso in segmenti di lunghezza variabile.
Un indirizzo di memoria è formato da <numero segmento; lunghezza segmento>.
Per ogni processo abbiamo una tabella dei segmenti, che mappa la coppia al corrispondente indirizzo fisico.
La segmentazione permette di vedere la memoria come uno spazio di indirizzi. C'è un problema però: i segmenti possono non essere contigui; in questo caso lo spazio degli indirizzi non è contiguo, ma frammentato.
Questo rende le cose un po' scomode e poco eleganti. Noi vorremmo un modo per astrarre questo meccanismo, e far sembrare al programmatore di avere uno spazio contiguo tutto per lui.
Riusciamo a compiere questo passo introducendo la memoria virtuale.
Intanto, per concludere il discorso, ti anticipo come risolviamo il problema.
Segmentazione su Paginazione (o Segmentazione Paginata)
Questo metodo combina segmentazione e paginazione. In pratica, usiamo la segmentazione per indirizzare le pagine.
In questo modo riusciamo ad astrarre la discontinuità dei segmenti, facendo credere al programma di avere uno spazio di indirizzi contiguo.
Segmenti e pagine rimangono discontinui in memoria, ma usiamo un sistema per – appunto – astrarre lo spazio degli indirizzi.
